巨头扎堆深耕产业AI,滴普科技以“本体大模型”升级AI落地模式
5月以来,企业AI赛道的风向彻底变了。 海外巨头率先吹响转向号角。先是Anthropic携手黑石、高盛成立企业AI服务公司,以将Claude嵌入企业核心运营;紧接着OpenAI成立Deployment Company,并通过收购Tomoro引入约150名Forward Deployed Engineers和部署专家,剑指企业级AI落地。 一个清晰的产业共识浮现。曾经轰轰烈烈的通用大模型“军备竞赛”,让位于企业级工程化能力的比拼。与此同时
5月以来,企业AI赛道的风向彻底变了。
海外巨头率先吹响转向号角。先是Anthropic携手黑石、高盛成立企业AI服务公司,以将Claude嵌入企业核心运营;紧接着OpenAI成立Deployment Company,并通过收购Tomoro引入约150名Forward Deployed Engineers和部署专家,剑指企业级AI落地。
一个清晰的产业共识浮现。曾经轰轰烈烈的通用大模型“军备竞赛”,让位于企业级工程化能力的比拼。与此同时,国内市场的企业AI应用也度过了早期的尝鲜与验证阶段,企业开始严肃思考AI能不能创造可量化的业务价值。
然而,再强大的通用模型,似乎仍与复杂的企业业务场景隔着一道无形的墙。
破局关键,究竟在哪里?
一、企业AI落地出现结构性瓶颈,通用模型的能力边界显现
其实早在海外厂商行动之前,国内政策已为这一产业转向指明方向。
2026年4月28日,工业和信息化部与国家数据局联合启动“模数共振”行动,明确提出重点面向钢铁、石化化工、有色金属等20个重点行业或领域,攻关“蕴含工业和信息化领域技术机理的行业模型、专用模型和特色智能体”,构建“行业通识和行业专识高质量数据集”。
几乎同时,国家网信办、国家发展改革委、工业和信息化部三部门于2026年5月8日联合印发《智能体规范应用与创新发展实施意见》,明确了智能体的核心定义与发展原则,并划定了19个典型应用场景。
两项政策都非常务实,并传递出同一信号,在企业AI的深水区,不能靠一个通用模型打天下,需要从模型能力走向数据、场景、行业知识与智能体能力的协同。
现实的确如此。无论是Claude、ChatGPT还是DeepSeek、豆包,它们的通用智能毋庸置疑,能写代码、能做总结、能模拟对话,但一旦进入制造、零售、金融等行业的深度业务场景,就立刻失灵。
滴普科技创始人、董事会主席、执行董事兼CEO赵杰辉在近期署名文章中指出,企业级AI落地的核心障碍在于通用模型缺乏“业务语义层Plan能力”。简单说,它看不懂业务对象在企业本体中的专属语义,分不清派生量节点并触发反向追溯,更无法在多目标、多规则约束下进行优先级仲裁与约束求解。
图: 业务语义层 Plan 的多种推理策略示意
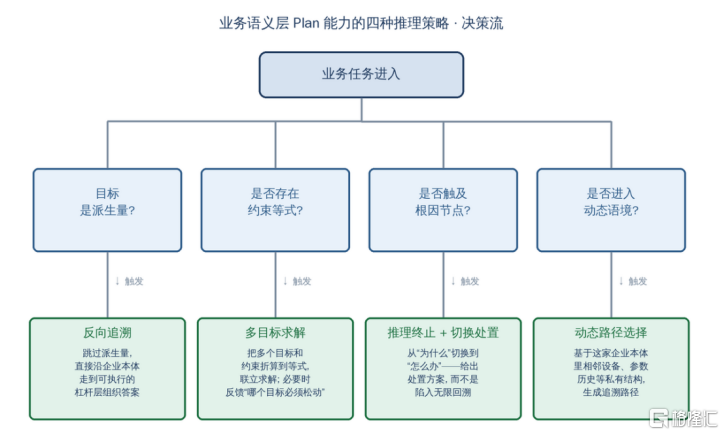
图片来源:《本体大模型,企业级智能体落地的产品化探索》,赵杰辉
换言之,通用大模型聪明,却未必懂行。
面对通用模型的失灵,滴普给出的解法,是跳出通用模型的思维定式,做懂业务的本体大模型。
滴普科技的本体大模型核心是Deepexi企业大模型。该模型建立在滴普八年服务近400家头部企业所积累的Deepology数据集之上。该数据集包含108个业务本体,并以静态结构层、路径模板层、现象级实例层三种范式构建,覆盖制造、零售、医疗、金融、政务等行业,是公开语料中从未存在过的行业Know-how。
更具体地说,Deepexi企业大模型的核心创新在于其两层Plan能力融合的架构。第一层是业务语义层Plan。它深入企业本体,专门内化了多种关键的业务推理策略,相当于为AI装备了理解业务、进行逻辑推演的大脑。第二层是通用执行层Plan,其语义底座是通用工具集,负责将业务意图翻译成具体的工具调用序列。通过这种架构,Deepexi企业大模型获得了在企业本体语义空间上进行规划与推理的独特能力。
图:本体大模型的两层 Plan架构
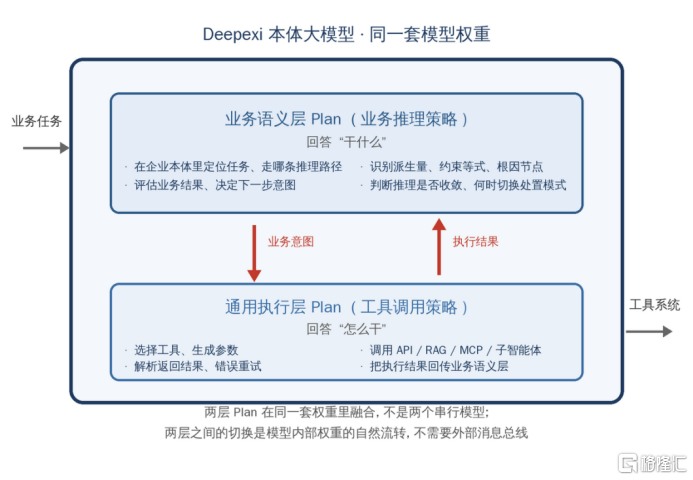
图片来源: 《本体大模型,企业级智能体落地的产品化探索》,赵杰辉
然而,当前资本市场关注的已经不是单纯的技术方案,而是产业意义,即AI能否重构企业AI的落地方式与盈利逻辑。
二、本体大模型升级FDE模式,重构企业AI Token经济学
具体来看,滴普科技的本体大模型路径,重构了企业级AI落地中两个深层模式。
首先,本体大模型是对经典FDE(前线驻扎工程师)模式的升级与重塑。
全球顶尖投资机构a16z曾指出,越来越多AI公司正在采用Palantir模式,不只卖软件或API,而是派出FDE深入客户现场,构建可运行的AI工作流。这也是Palantir受资本市场追捧的关键。
目前,Palantir、Anthropic、OpenAI等海外企业都在加码探索FDE模式,而国内已有厂商采取着相似的服务模式,滴普科技正是其中的代表。
但与Palantir推出了AI FDE来操作其Foundry平台不同,滴普科技选择的则是本体推理能力训练进模型权重,将边的程序语义、推理动作的条件反射直接编码为模型参数中的能力,并通过Deepexi Foil作为本体的存储与演化载体。
赵杰辉直言,用大模型完成FDE的部分工作,是产业演进的必然方向。滴普科技并不是要取代人类专家,而是把FDE工作中重复、通用的环节,用模型实现自动化。
另一方面,本体大模型重构了企业AI的Token经济学。
“企业AI落地是一道Token经济题,”赵杰辉总结,“通用模型把Token单价压下来,Deepexi把Token的业务密度提上去。”
当前,DeepSeek V4等模型以“价格屠夫”姿态出现,Token基础成本正快速下降,成为廉价的数字生产资料。但问题在于,通用模型只能降本,却不懂业务。海量Token消耗下去,大多是无效算力浪费,用得越多,浪费越严重。本体大模型则补齐这一短板,致力于让每一次推理和工具调用都精准指向业务目标,从而极大提升每个token所承载的业务价值密度。
滴普科技还在此基础上更进一步。通用模型负责将成本做低,本体大模型负责将价值做高,两者在FastAGI企业智能体平台上协同,形成可盈利的商业算式。
这套逻辑,已经在滴普2025年财报中得到了验证。其FastAGI业务收入同比暴增181.5%至2.54亿元,成为增长主引擎,这推动公司整体营收同比增长70.8%,同时亏损大幅收窄。尤其是,在此过程中,滴普科技从项目制向Token消耗与AI员工订阅制的商业模式转型;换而言之,滴普科技蜕变成一个与Token经济发展、产业价值增长深度绑定的生态型平台。
值得一提的是,a16z曾一针见血地指出,如果每个客户都都需要无限堆人服务,那只是咨询业务;真正的好公司应该随着客户成熟,不断降低服务成本、提升平台复用率。
Deepexi采用的三层训练架构巧妙地破解了AI落地规模不经济的魔咒。三层训练架构是能力训练(跨企业复用)—行业本体持续预训练(同行业复用)—客户本体注入(企业专属)的递进模式,前两层高昂的固定研发成本可随客户规模扩大被快速摊薄,只有体量最小的第三层才是客户专属投入。这使得单家客户的交付成本随规模效应显著降低,面向单一大客户的深度交付在经济上变得可行。
毕竟,企业AI落地的终极目标,从来不是技术多先进,而是效率够高、能赚钱。
结语
企业AI的通用时代已经落幕,本体时代正在登场。
政策导向、巨头动作、市场需求,都在指向新的方向,即AI必须扎根产业、懂业务、能落地。滴普的本体大模型,本质上是提供了一条技术适配业务、价值优先于成本的务实路径。
或许就是企业AI下一个十年的核心主线。











